When a Big Data project fails, there’s plenty of blame to go around. When I do the retrospectives with teams who are failing or about to fail, their blame is often misplaced. There’s a focus on blaming the technology. The more difficult considerations of looking inwards at the team itself is often skipped.
The teams who never look at themselves are fated to fail over and over, while trying new technologies. Instead, they need to look inwards at the team to figure out why they’re failing. These issues are especially prevalent in Big Data due to its increase in complexity.
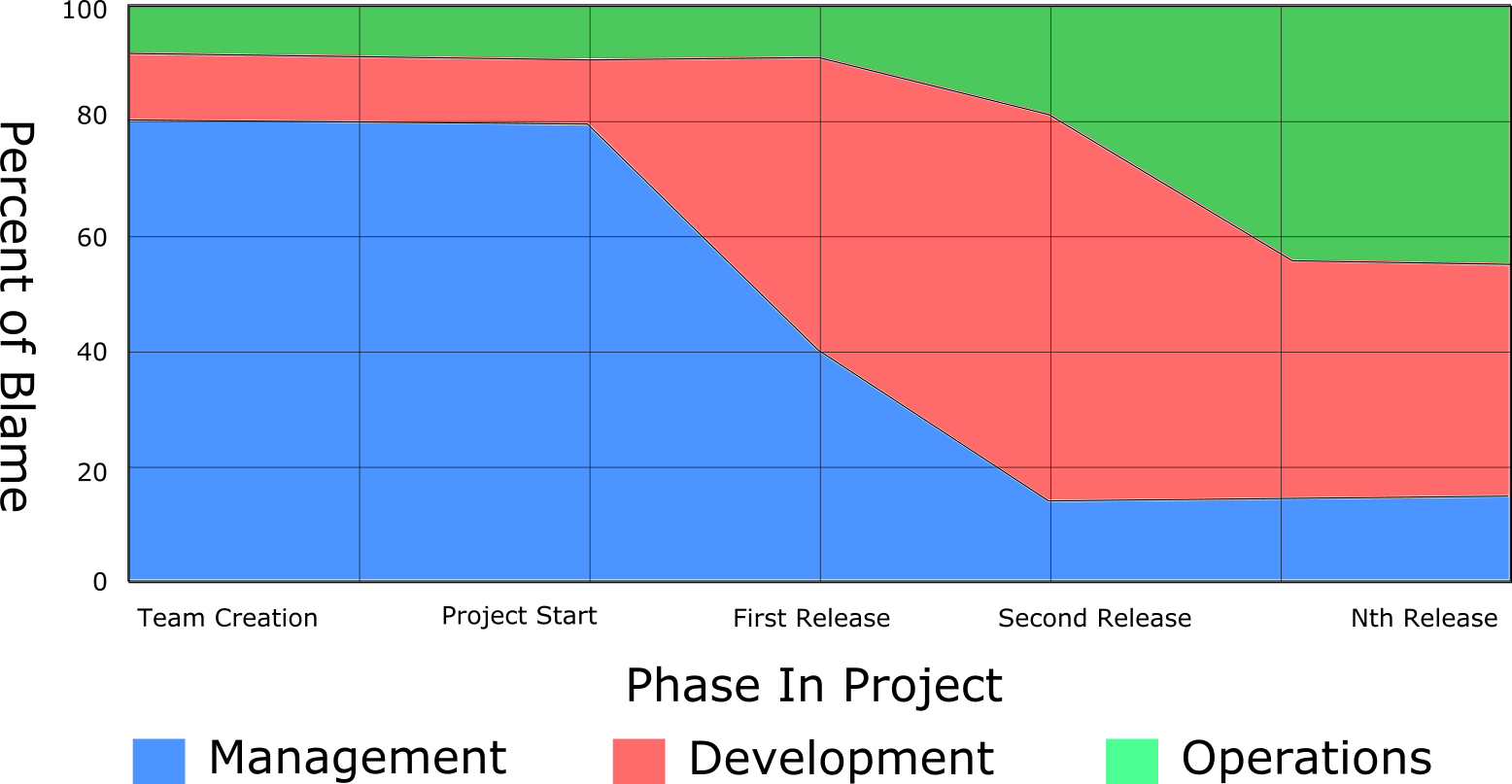
In this chart, I break down when teams fail in the different phases, how often a particular function is to blame, and which function is to blame.
Management
In the early phases of a project, the management team is responsible for the majority of failures. If management isn’t actually creating the project, how can they be responsible for a failure?
In chapter 3 “Data Engineering Teams” of my book Data Engineering Teams. If management starts a data engineering project without checking the team for skill and ability gaps, they are responsible for the team’s impending failure. Failing to give the team resources to learn the new technologies is a management responsibility.
According to Gartner, 85% of Big Data projects fail. The report doesn’t talk about when and why they fail. In my experience, they fail in the “team creation” and “project start” phases. The final failure or the actual cancellation might come later, but the major problems started at the very beginning.
Over time, management’s percent of blame goes down dramatically. From the second release on, the management team needs to give the development and operations teams the time to keep up with changes and new technologies.
In these late stages, management is to blame for preventing the team from paying down any technical debt. If the development team had to skip or shortcut for a faster design, they will need the time to go back and implement things right. With software and systems as complicated as Big Data pipelines, the teams need the time fix the code.
Development
As the project starts to mature and code is being written, the percent of blame goes up for the development team. Now, it’s their responsibility to create the solution.
Developers can fail in projects by underestimating the increase in complexity from moving to Big Data. This comes from overconfidence or thinking that Big Data is just like small data. Developers that come into my classes with underestimations quickly learn this is a different story.
Developer teams may need to improve their existing skills or acquire brand new skills. These brand new skills are the Big Data technologies themselves. Some developers are able to leverage their distributed systems backgrounds and learn Big Data from a book. Most developers can’t. They need extra help to learn the technologies.
Another common failure scenario is to start choosing technologies or implement the solution without understand the use case. If a team doesn’t understand the use case, they can choose technologies that either can’t handle the use case or make the implementation take significantly longer.
This drives us to the importance of a developer team choosing the right technologies. A Data Engineer chooses the right technologies by knowing 20-30 different technologies. Big Data isn’t a time when you can use the same 3 technologies to write any program. Rather, Big Data requires the right tool for the job.
Operations
As time goes on, the operations team become responsible for more of the project’s success. Even if you’re using a UI such as Cloudera Manager or using the Cloud, your operations team will need new skills.
If the operations team lacks Linux skills, they’ll need to acquire them. Most Big Data frameworks are written and tested for Linux.
Running a cluster in the Cloud doesn’t remove the need for operations. It just reduces the number of people your operations team needs.
What You Should Do
If you’re embarking on a Big Data project, learn from others’ failures. Treating Big Data just like small data is one of those keys.